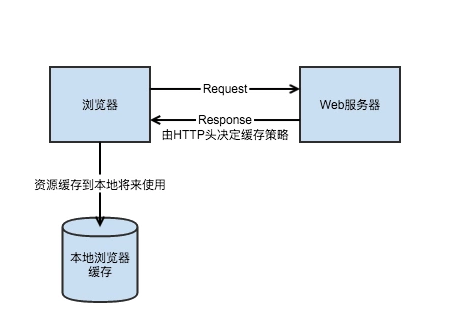
一:什么是分片上传?
分片上传是把一个大的文件分成若干块,一块一块的传输。这样做的好处可以减少重新上传的开销。比如:
如果我们上传的文件是一个很大的文件,那么上传的时间应该会比较久,再加上网络不稳定各种因素的影响,很容易导致传输中断,用户除了重新上传文件外没有其他的办法,但是我们可以使用分片上传来解决这个问题。通过分片上传技术,如果网络传输中断,我们重新选择文件只需要传剩余的分片。而不需要重传整个文件,大大减少了重传的开销。
如下图是一个大文件分成很多小片段:
但是我们要如何选择一个合适的分片呢?
因此我们要考虑如下几个事情:
- 分片越小,那么请求肯定越多,开销就越大。因此不能设置太小。
- 分片越大,灵活度就少了。
- 服务器端都会有个固定大小的接收Buffer。分片的大小最好是这个值的整数倍。
因此,综合考虑到推荐分片的大小是2M-5M. 具体分片的大小需要根据文件的大小来确定,如果文件太大,建议分片的大小是5M,如果文件相对较小,那么建议分片的大小是2M。
实现文件分片上传的步骤如下:
- 先对文件进行md5加密。使用md5加密的优点是:可以对文件进行唯一标识,同样可以为后台进行文件完整性校验进行比对。
- 拿到md5值以后,服务器端查询下该文件是否已经上传过,如果已经上传过的话,就不用重新再上传。
- 对大文件进行分片。比如一个100M的文件,我们一个分片是5M的话,那么这个文件可以分20次上传。
- 向后台请求接口,接口里的数据就是我们已经上传过的文件块。(注意:为什么要发这个请求?就是为了能续传,比如我们使用百度网盘对吧,网盘里面有续传功能,当一个文件传到一半的时候,突然想下班不想上传了,那么服务器就应该记住我之前上传过的文件块,当我打开电脑重新上传的时候,那么它应该跳过我之前已经上传的文件块。再上传后续的块)。
- 开始对未上传过的文件块进行上传。(这个是第二个请求,会把所有的分片合并,然后上传请求)。
- 上传成功后,服务器会进行文件合并。最后完成。
二:理解Blob对象中的slice方法对文件进行分割及其他知识点
在编写代码之前,我们需要了解一些基本的知识点,然后在了解基础知识点之上,我们再去实践我们的大文件分片上传这么的一个demo。
- 首先我们来看下我们的Blob对象,如下代码所示:
1 | var b = new Blob(); |
如下所示:

如上图我们可以看到,我们的Blob对象自身有 size 和 type两个属性,及它的原型上有 slice() 方法。我们可以通过该方法来切割我们的二进制的Blob对象。
- 学习 blob.slice 方法
blob.slice(startByte, endByte) 是Blob对象中的一个方法,File对象它是继承Blob对象的,因此File对象也有该slice方法的。
参数:
startByte: 表示文件起始读取的Byte字节数。
endByte: 表示结束读取的字节数。
返回值:var b = new Blob(startByte, endByte); 该方法的返回值仍然是一个Blob类型。
我们可以使用 blob.slice() 方法对二进制的Blob对象进行切割,但是该方法也是有浏览器兼容性的,因此我们可以封装一个方法:如下所示:
1 | function blobSlice(blob, startByte, endByte) { |
- 理解 async/await 的使用
在我很早之前,我已经对async/await 的使用和优势做了讲解,有兴趣了解该知识点的,可以看我之前这篇文章.
因此我们现在来看下如下demo列子:
1 | const hashFile2 = function(file) { |
如上代码,如果我们直接刷新页面,就可以在控制台中输出 111 这个的字符。为什么我现在要讲解这个呢,因为待会我们的demo会使用到该知识点,所以提前讲解下理解下该知识。
- 理解 FileReader.readAsArrayBuffer()方法
该方法会按字节读取文件内容,并转换为 ArrayBuffer 对象。readAsArrayBuffer方法读取文件后,会在内存中创建一个 ArrayBuffer对象(二进制缓冲区),会将二进制数据存放在其中。通过此方式,我们就可以直接在网络中传输二进制内容。
其语法结构:
1 | FileReader.readAsArrayBuffer(Blob|File); |
Blob|File 必须参数,参数是Blob或File对象。
如下代码演示:
1 | <!DOCTYPE html> |
如果我们现在上传的是文本文件的话,就会打印如下信息,如下所示:
三.使用 spark-md5 生成 md5文件
了解spark-md5,请看npm官网
下面我们来理解下 上传文件如何来得到 md5 的值。上传文件简单的如下demo, 代码所示:
1 | <!DOCTYPE html> |
如上代码,首先我在 input type = ‘file’ 这样的会选择一个文件,然后点击进行上传,先获取文件的大小,然后定义一个分片的大小默认为2兆,使用 var chunks = Math.ceil(fileSize / chunkSize); // 获取切片的个数 方法获取切片的个数。
如果 fileSize(文件大小) 小于 chunkSize(2兆)的话,使用向上取整,因此为1个分片。同理如果除以的结果 是 1.2 这样的,那么就是2个分片了,依次类推…. 然后使用 SparkMD5.ArrayBuffer 方法了,详情可以看官网(http://npm.taobao.org/package/spark-md5). 先初始化当前的 currentChunk 分片为0,然后 reader.onload = function(e) {} 方法,如果当前的分片数量小于 chunks 的数量的话,会继续调用 loadNext()方法,该方法会读取下一个分片,开始的位置计算方式是:var start = currentChunk chunkSize;
currentChunk 的含义是第二个分片(从0开始的,因此这里它的值为1),结束的位置 计算方式为:
var end = start + chunkSize > file.size ? file.size : (start + chunkSize);
也就说,如果一个文件的大小是2.1兆的话,一个分片是2兆的话,那么它就最大分片的数量就是2片了,但是 currentChunk 默认从0开始的,因此第二个分片,该值就变成1了,因此 start的位置就是 var start = 1 2(兆)了,然后 var end = start + chunkSize > file.size ? file.size : (start + chunkSize);
如果 start + chunkSize 大于 文件的大小(file.size) 的话,那么就直接去 file.size(文件的大小),否则的话,结束位置就是 start + chunkSize 了。最后我们使用
blobSlice 进行切割,就切割到第二个分片的大小了,blobSlice.call(file, start, end),这样的方法。然后把切割的文件读取到内存中去,使用 reader.readAsArrayBuffer() 将buffer读取到内存中去了。继续会调用 onload 该方法,直到 进入else 语句内,那么 const md5 = spark.end(); 就生成了一个md5文件了。如上代码,如果我现在上传一个大文件的话,在控制台中就会打印如下信息了:如下图所示:
四. 使用koa+js实现大文件分片上传实践
注:根据网上demo来讲解的
先看下整个项目的架构如下:1
2
3
4
5
6
7
8
9
10
11|---- 项目根目录
| |--- app.js # node 入口文件
| |--- package.json
| |--- node_modules # 所有依赖的包
| |--- static # 存放静态资源文件目录
| | |--- js
| | | |--- index.js # 文件上传的js
| | |--- index.html
| |--- uploads # 保存上传文件后的目录
| |--- utils # 保存公用的js函数
| | |--- dir.js
static/index.html 文件代码如下:
1 | <!DOCTYPE html> |
运行页面,效果如下所示:
static/js/index.js 代码如下:
1 | $(document).ready(() => { |
如上代码,和我们上面生成md5代码很类似,从添加到formData下面的代码不一样了,我们可以来简单的分析下,看下代码的具体含义:
1 | const blockCount = Math.ceil(file.size / chunkSize); // 分片总数 |
上面的代码的含义是获取分片的总数,我们之前讲解过,然后使用 for循环遍历分片,依次把对应的分片添加到 formData数据里面去,如下所示代码:
1 | const axiosPromiseArray = []; |
如上代码,循环分片的总数,然后依次实列化formData数据,依次放入到formData实列中,然后分别使用 ‘/file/upload’ 请求数据,最后把所有请求成功的数据放入到 axiosPromiseArray 数组中,当所有的分片上传完成后,我们会使用 await axios.all(axiosPromiseArray).then(() => {}) 方法,最后我们会使用 ‘/file/merge_chunks’ 方法来合并文件。
下面我们来看看 app.js 服务器端的代码,如下所示:
1 | const Koa = require('koa'); |
如上代码:分别引入 koa, koa-router, koa-multer, koa-static, path, fs-extra, koa-body 依赖包。
koa-multer 的作用是为了处理上传文件的插件。
utils/dir.js 代码如下(该代码的作用是判断是否有这个目录,有这个目录的话,直接返回true,否则的话,创建该目录):
1 | const path = require('path'); |
- /file/upload 请求代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17router.post('/file/upload', upload.single('file'), async (ctx, next) => {
console.log('file upload...')
// 根据文件hash创建文件夹,把默认上传的文件移动当前hash文件夹下。方便后续文件合并。
const {
name,
total,
index,
size,
hash
} = ctx.req.body;
const chunksPath = path.join(uploadPath, hash, '/');
if(!fs.existsSync(chunksPath)) mkdirsSync(chunksPath);
fs.renameSync(ctx.req.file.path, chunksPath + hash + '-' + index);
ctx.status = 200;
ctx.res.end('Success');
})
如上代码,会处理 ‘/file/upload’ 这个请求,upload.single(‘file’), 的含义是:接受一个文件名称字段名。
单一文件将存储在req.file中,这是 koa-multer 插件的用法,具体可以看 koa-multer官网(https://www.npmjs.com/package/koa-multer)。 获取到文件后,请求成功回调,然后会在项目中的根目录下创建一个 uploads 这个目录,如下代码可以看到:
1 | const uploadPath = path.join(__dirname, 'uploads'); |
最后上传完成后,我们可以在我们的项目中可以看到我们所有的文件都在我们本地了,如下所示:
我们也可以在我们的网络中看到如下很多 ‘/file/upload’ 的请求,如下可以看到很多请求,说明我们的请求是分片上传的,如下所示:
- ‘/file/merge_chunks’
最后所有的分片请求上传成功后,我们会调用 ‘/file/merge_chunks’ 这个请求来合并所有的文件,根据我们的hash值,来获取文件分片。
如下代码:
1 | // 根据hash值,获取分片文件。 |
如上代码,会循环分片的总数,然后把所有的分片写入到我们的filePath目录中,如这句代码:
1 | fs.appendFileSync(filePath, fs.readFileSync(chunksPath + hash + '-' +i)); |
其中 filePath 的获取 是这句代码:const filePath = path.join(uploadPath, name); 也就是说在我们项目的根目录下的uploads文件夹下,这么做的原因是为了防止网络突然断开或服务器突然异常的情况下,文件上传到一半的时候,我们本地会保存一部分已经上传的文件,如果我们继续上传的时候,我们会跳过哪些已经上传后的文件,继续上传未上传的文件。这是为了断点续传做好准备的,下次我会分析下如何实现断点续传的原理了。如果我们把上面这两句代码注释掉,如下所示:
1 | // 删除本次使用的chunk |
我们就可以看到我们项目本地会有 uploads 会有很多分片文件了,如下所示:
当我们这个文件上传完成后,如上代码,我们会把它删除掉,因此如果我们不把该代码注释掉的话,是看不到效果的。
如果我们继续上传另外一个文件后,会在我们项目的根目录下生成第二个文件,如下所示: